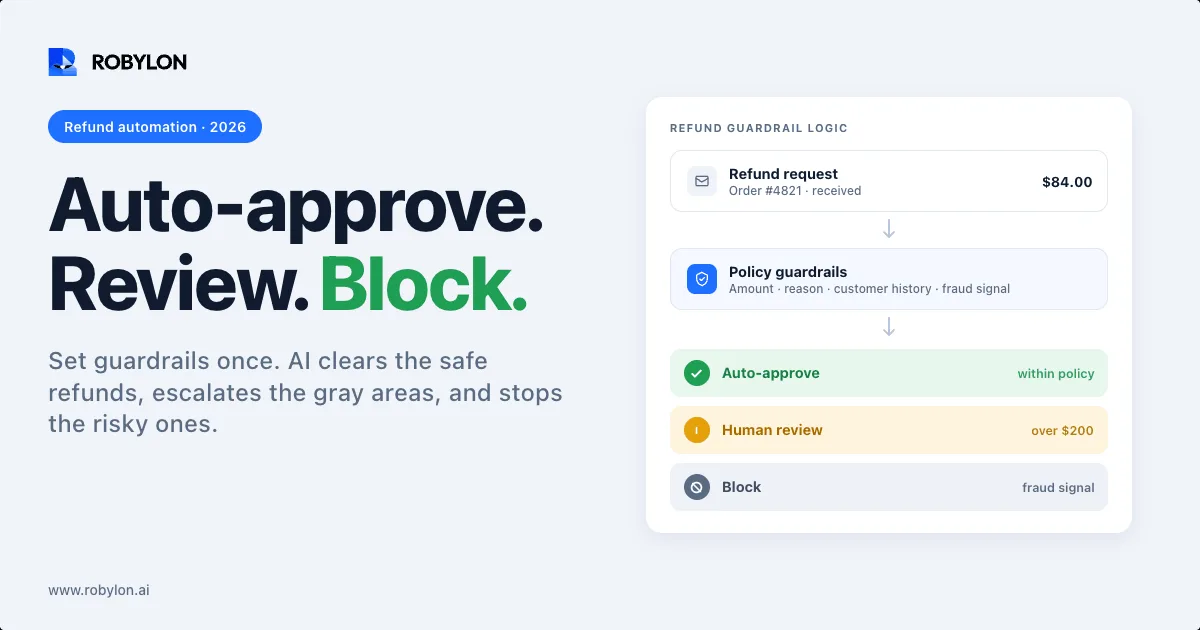
.png)

"What if the AI sends wrong answers to customers?" This is the number one objection support leaders raise when evaluating AI email automation. It is a legitimate concern — an inaccurate email response damages customer trust, creates follow-up work, and can cause real harm in regulated industries. But the question should not be "Can AI be accurate?" — it should be "How do I make AI accurate enough to trust?"
The answer is a systematic approach to knowledge base optimization, confidence calibration, and continuous improvement. Teams that follow this approach consistently achieve 95%+ accuracy within 8–12 weeks of deployment — outperforming the typical human accuracy rate of 85–92%.
What "Accuracy" Actually Means for Email AI
Accuracy is not a single metric. For email support, it breaks into four components: factual accuracy (is the information in the response correct?), intent accuracy (did the AI correctly understand what the customer was asking?), completeness (did the response address every question in the email?), and action accuracy (if the AI took an action — processed a refund, updated an address — was the action correct?).
A response that correctly answers the customer's question but misses their second question is factually accurate but incomplete. A response that processes a refund correctly but quotes the wrong refund timeline is action-accurate but factually inaccurate. Tracking all four components separately reveals where to focus optimization efforts.
The Accuracy Maturity Curve
Week 1–2: Shadow Mode (75–85% Accuracy)
During shadow mode, the AI processes every email and generates draft responses, but nothing is sent to customers. Your team reviews every draft and flags errors. Accuracy at this stage is typically 75–85% — the AI gets the basic intent right most of the time but makes errors on edge cases, outdated information, and complex multi-part emails.
This is normal and expected. Shadow mode is not a test of whether the AI works — it is a diagnostic that reveals exactly where it needs improvement. The errors are your roadmap.
Week 3–4: Early Live (85–90% Accuracy)
After fixing the issues identified in shadow mode — updating KB articles, adding missing content, correcting outdated information — accuracy jumps to 85–90%. You enable auto-resolution for the highest-confidence categories (WISMO, simple FAQs) where accuracy is already 95%+, and keep medium-confidence categories in draft mode.
Week 5–8: Optimization (90–95% Accuracy)
Each week, close the top 5 knowledge gaps and accuracy errors from the previous week. Add nuances the AI is missing — conditional policies (returns accepted within 14 days for sale items, 30 days for full-price), exception handling (what to do when the order number is not found), and multi-issue parsing improvements. Accuracy climbs to 90–95% across all categories.
Week 9–12: Mature (95%+ Accuracy)
By this stage, the AI has been trained on 8–12 weeks of real email traffic. The knowledge base has been refined based on actual customer questions (not guesses about what customers ask). Confidence thresholds are calibrated to category-specific accuracy data. The AI achieves 95%+ accuracy on auto-resolved emails, with the remaining errors concentrated in genuinely novel or ambiguous queries that would challenge human agents too.
The Six Levers for Improving Accuracy
Lever 1: Knowledge Base Quality
The AI is only as accurate as its source material. The most common accuracy errors trace back to knowledge base problems: outdated articles (policy changed but the article was not updated), missing content (customer asks about a topic not covered in the KB), ambiguous phrasing (the article says "typically 3–5 days" and the AI picks a specific number), and conflicting information (two articles give different answers to the same question).
Action: audit your top 20 KB articles (the ones the AI retrieves most frequently) for accuracy, clarity, and currency. Rewrite ambiguous sections as clear, conditional statements. Remove or update any outdated content. This single step typically improves accuracy by 5–10 percentage points.
Lever 2: Confidence Threshold Calibration
The confidence threshold determines which responses the AI sends automatically versus queuing for human review. Setting it too low lets inaccurate responses through. Setting it too high forces too many emails to human review, defeating the purpose of automation.
The optimal approach: set category-specific thresholds based on observed accuracy data. WISMO (where accuracy is 97%+) can have a threshold of 82%. Refund requests (where accuracy is 90%) need a threshold of 90%. Billing queries (where accuracy is 88%) need 92%. This calibration maximizes auto-resolution while maintaining quality standards for each category individually.
Lever 3: Multi-Issue Email Handling
15–20% of support emails contain multiple questions. AI accuracy drops on these because the model may address some questions while missing others, or it may conflate two issues into one response. Improvement requires structured multi-intent parsing: the AI must decompose the email into separate intents, retrieve knowledge for each independently, resolve each separately, and then compose a response that addresses all of them coherently.
Test multi-issue handling explicitly: send test emails with 2, 3, and 4 distinct questions and verify the AI addresses each one. Most accuracy gains in weeks 5–8 come from improving multi-issue handling.
Lever 4: Attachment and Context Processing
Customers attach screenshots, invoices, and order confirmations to emails. If the AI cannot process these attachments, it misses critical context — leading to responses that ignore the attached evidence. Configure your AI platform to extract text from images (OCR), parse PDF content, and incorporate attachment data into the response. A customer who attaches a screenshot of an error message expects the AI to acknowledge and address what is shown in the screenshot.
Lever 5: Feedback Loop Speed
Every inaccurate AI response is a training opportunity — but only if the feedback reaches the system quickly. Build a fast feedback loop: agents who review AI drafts or handle escalations from AI errors flag the specific issue (wrong fact, missed question, wrong action, wrong tone) with one click. The flagged issue feeds directly into the next knowledge base update cycle. The best teams run this cycle weekly — flag on Monday through Friday, update KB on Friday, improved accuracy visible by the following Monday.
Lever 6: Edge Case Libraries
Some accuracy errors come from genuine edge cases — unusual situations the knowledge base does not cover because they are rare. Rather than trying to anticipate every edge case, build an edge case library: when the AI encounters a query it cannot confidently resolve, log it. When the same edge case appears 3+ times, write a KB article for it. This approach ensures your knowledge base grows based on real customer needs, not hypothetical scenarios.
Measuring and Reporting Accuracy
Track accuracy weekly across three views: overall accuracy (target: 95%+), accuracy by category (identify which categories are above and below target), and accuracy trend (is accuracy improving week over week?). The most actionable report is the category-level breakdown — it tells you exactly where to focus your optimization effort this week.
Spot-check methodology: review a random sample of 50 AI-resolved emails per week across categories. For each response, score four dimensions (factual accuracy, intent accuracy, completeness, action accuracy) as correct or incorrect. Calculate the percentage correct for each dimension and overall. This takes 1–2 hours per week and provides the data you need to calibrate thresholds and prioritize KB improvements.
Bottom Line
95%+ accuracy in AI email support is achievable — and in many cases, it exceeds human accuracy (85–92%) because the AI applies knowledge consistently, does not have bad days, and does not forget to check the latest policy update. The path to 95% is systematic: optimize your knowledge base, calibrate confidence thresholds by category, improve multi-issue handling, process attachments, maintain a fast feedback loop, and build an edge case library.
The teams that achieve the highest accuracy share one trait: they treat AI email support as a system to be tuned, not a product to be deployed and forgotten. Thirty minutes per week of knowledge base optimization produces compounding accuracy gains that reach 95%+ within 8–12 weeks.
Achieve 95%+ email accuracy. Robylon AI surfaces knowledge gaps, tracks accuracy by category, and provides a one-click feedback loop for continuous improvement. Start free at robylon.ai
FAQs
How do I spot-check AI email accuracy effectively?
Review a random sample of 50 AI-resolved emails per week across categories. For each response, score 4 dimensions (factual accuracy, intent accuracy, completeness, action accuracy) as correct/incorrect. Calculate percentage correct overall and per dimension. This takes 1–2 hours per week and produces the data needed to calibrate thresholds and prioritize KB improvements. Focus on category-level accuracy — it tells you exactly where to invest optimization effort.
Should I use the same confidence threshold for all email categories?
No — use category-specific thresholds based on observed accuracy. WISMO (97%+ accuracy): threshold at 82%. Refund requests (90% accuracy): threshold at 90%. Billing queries (88% accuracy): threshold at 92%. This calibration maximizes auto-resolution per category while maintaining quality standards. A single threshold forces a compromise — too high for easy categories (unnecessary human review) or too low for sensitive ones (inaccurate responses slip through).
What is the biggest lever for improving AI email accuracy?
Knowledge base quality. The most common accuracy errors trace to KB problems: outdated articles, missing content, ambiguous phrasing, and conflicting information. Auditing your top 20 most-retrieved articles for accuracy, clarity, and currency typically improves overall accuracy by 5–10 percentage points in a single effort. After the initial audit, closing the top 5 knowledge gaps weekly adds 2–5 percentage points per week for the first 2–3 months.
What are the four components of AI email accuracy?
1) Factual accuracy: Is the information correct? (Verified against KB and live systems.) 2) Intent accuracy: Did the AI understand what the customer was asking? 3) Completeness: Did the response address every question in the email? 4) Action accuracy: If the AI took an action (refund, address update), was it correct? Track all four separately — a response can be factually accurate but incomplete (addressed 2 of 3 questions), requiring different fixes for each component.
How long does it take to achieve 95% accuracy with AI email support?
Typically 8–12 weeks following a systematic approach: Week 1–2 (shadow mode): 75–85% accuracy — baseline diagnostic. Week 3–4 (early live): 85–90% after fixing issues found in shadow mode. Week 5–8 (optimization): 90–95% through weekly KB gap closure and threshold calibration. Week 9–12 (mature): 95%+ with remaining errors concentrated in genuinely novel queries. The key driver is consistent weekly KB optimization — 30 minutes per week closing the top 5 knowledge gaps.
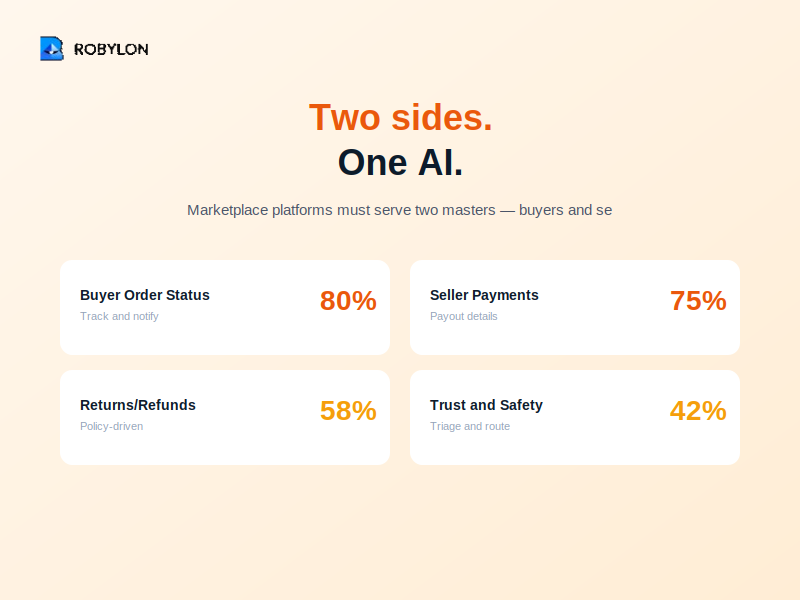
.png)





.webp)